
模型蒸馏不只是压缩:从教师模型到后训练技术栈
蒸馏是把大模型的行为、偏好和推理轨迹迁移到更小模型的一种训练系统。真正落地时,它会和 SFT、LoRA、QLoRA、DPO/RLHF、RLAIF、量化、剪枝、MoE、自训练和评测闭环一起工作。
AILLMTraining
蒸馏是把大模型的行为、偏好和推理轨迹迁移到更小模型的一种训练系统。真正落地时,它会和 SFT、LoRA、QLoRA、DPO/RLHF、RLAIF、量化、剪枝、MoE、自训练和评测闭环一起工作。
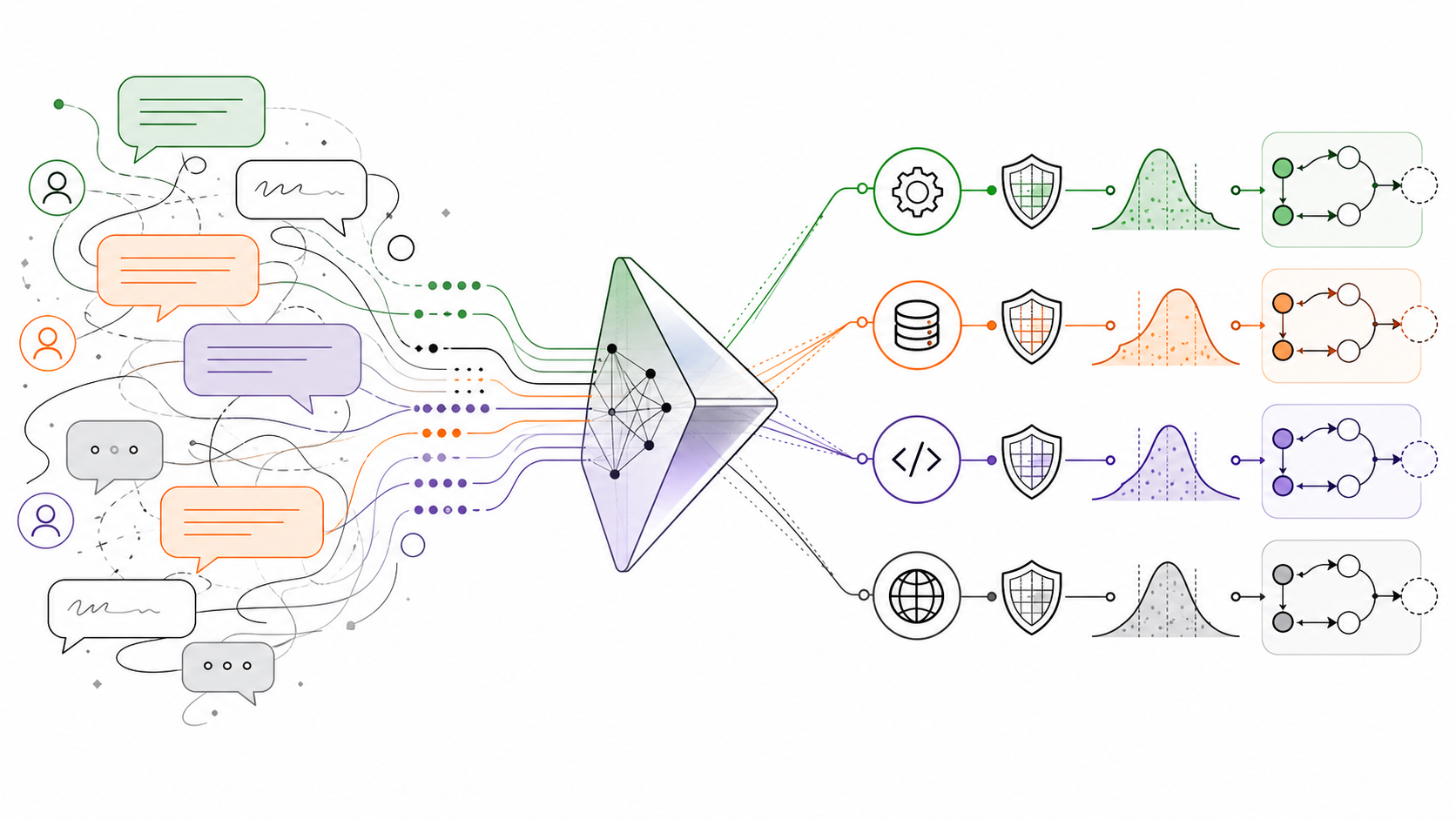
Agent 时代的意图识别已经从单轮 intent classification 演变成 intent routing:它要处理多意图、多轮上下文、越界检测、工具选择、风险分级和不确定性门控。

近期 X 上围绕 Fable、Mythos、Five Eyes 警告和模型出口控制的讨论,说明前沿模型正在从产品问题变成基础设施和国家安全问题。技术团队需要把红队、准入、审计和可中断部署前移。

最近 X 上围绕 Noam Shazeer、John Jumper 和 AI 顶级人才流动的讨论,表面是跳槽八卦,实质是市场在重新给模型公司的人才、产品速度和组织吸引力定价。

企业开始部署 AI agent 后,真正的工程重点会从 prompt 转到控制平面:身份、权限、上下文、工具、评估、成本、审计和失败恢复。

GPU 集群一旦多租户,就不能只靠命名空间隔离。镜像、RBAC、RuntimeClass、Device Plugin、ResourceClaim、secret、网络和节点池都要有硬边界。

企业 AI 的价值正在从“生成内容”转向“完成业务闭环”。客服、金融、零售和运营场景的共同点,是 AI 能接入数据、判断意图、推动下一步动作,并留下可评估结果。

企业 AI 已经从“给员工一个聊天框”进入“重写工作系统”的阶段。真正能落地的项目,不是模型演示,而是把知识、流程、权限、评估和组织学习连成闭环。

2026 年的 Agent 记忆系统已经不再是“向量库 + top-k”。更稳妥的生产方案是事件日志做真源,语义、情景、图谱、程序性记忆做多层投影,再用准入门控控制哪些记忆能进入上下文。

GPU 平台的容量规划要把训练 GPU 小时、推理 tokens/sec、P95 延迟、KV cache、队列等待和失败重试放到一张账本里。卡数只是输入,不是答案。

围绕 OpenAI、Anthropic 和 SpaceX 的 IPO 与融资讨论,本质是在问 AI 公司能否把算力支出、模型价格和企业收入讲成一个可持续资本故事。

OpenAI、Anthropic 等前沿实验室一边提醒风险一边发布强模型,真正的问题不是态度是否真诚,而是发布系统是否能被外部验证。

tokenmaxxing 从热潮变成反思,企业开始发现 AI token 消耗不是生产力指标,而是成本、路由和 ROI 的压力测试。

美国政府对 Fable 5 和 Mythos 5 的限制说明,前沿 AI 已经从 SaaS 服务变成战略基础设施,企业需要重新设计模型依赖和降级路径。

Fable 5 的游戏通关、研究工具和金融分析案例说明,强 Agent 的核心不是单次推理,而是视觉输入、工作记忆、行动策略和验收反馈的组合。

多模态和 RAG 不是在 LLM 前面加个向量库。它们会引入 embedding、reranker、OCR、图像编码、对象存储、缓存和异步索引流水线。
Fable 5 的关键不是某个榜单多高,而是长任务、工具调用、视觉输入、安全路由和成本控制同时进入同一个评测闭环。

Stripe 级代码迁移案例的价值,不是模型能写很多 patch,而是它把依赖发现、改写计划、测试门禁和人工验收压缩成一条迁移流水线。
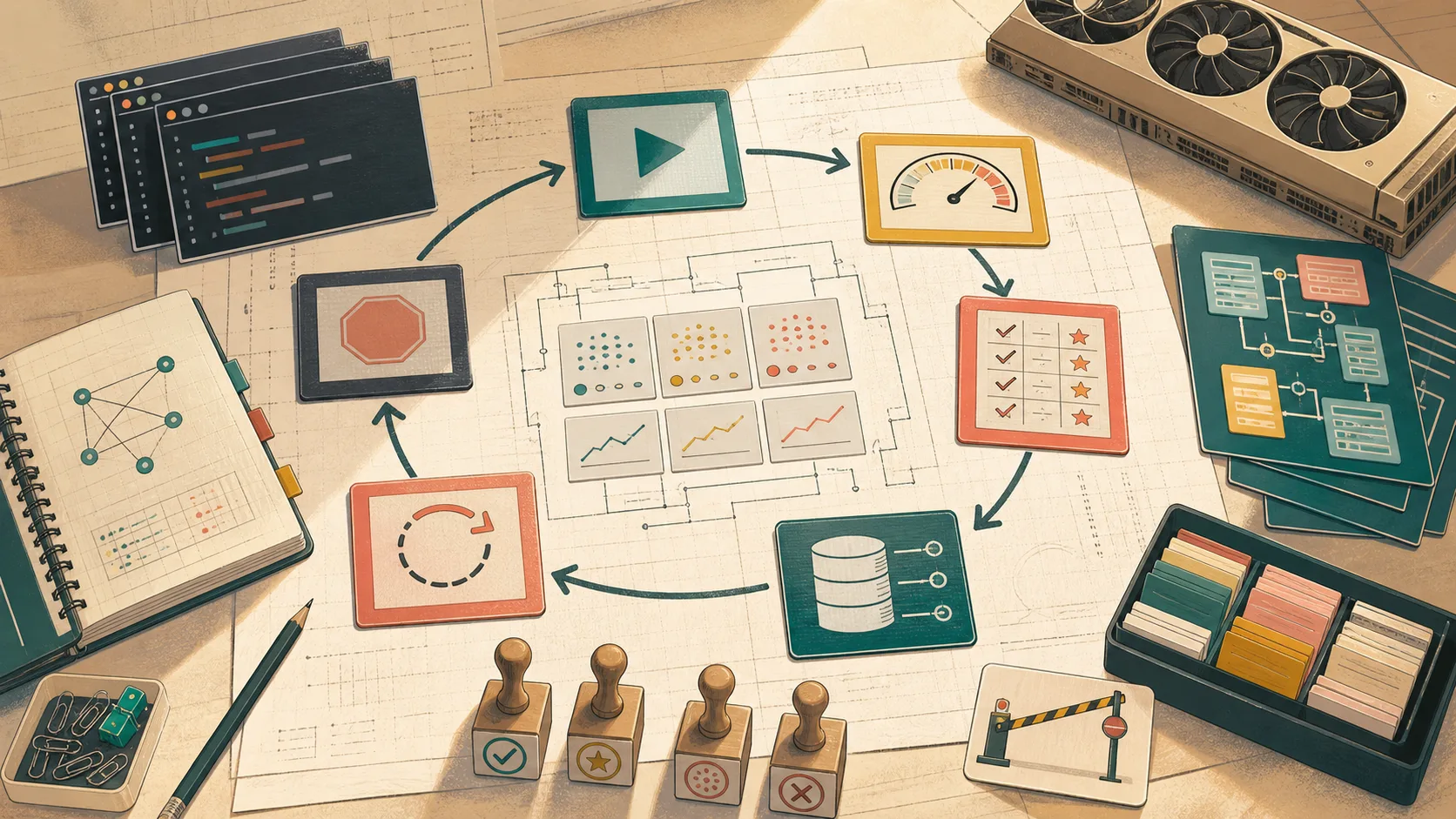
Fable 5 更适合放进有反馈、有独立验收、有外部记忆的长任务循环里,而不是当成更贵的默认模型。本文给出一套可落地的闭环方案。

实操篇:把计划、执行、验证、观测、记忆和清洁交接连起来,形成可长期运行的 Agent 工作闭环。

Loop Engineering 的重点不是写更长的 prompt,而是把发现、计划、执行、验证、记忆和再次触发做成一个可审计、可恢复、可控成本的系统。

Sierrana 不靠锦化取胜,而是靠更原生、更大叶、更有野性气质的成熟形态。它适合喜欢物种感和空间感的玩家。
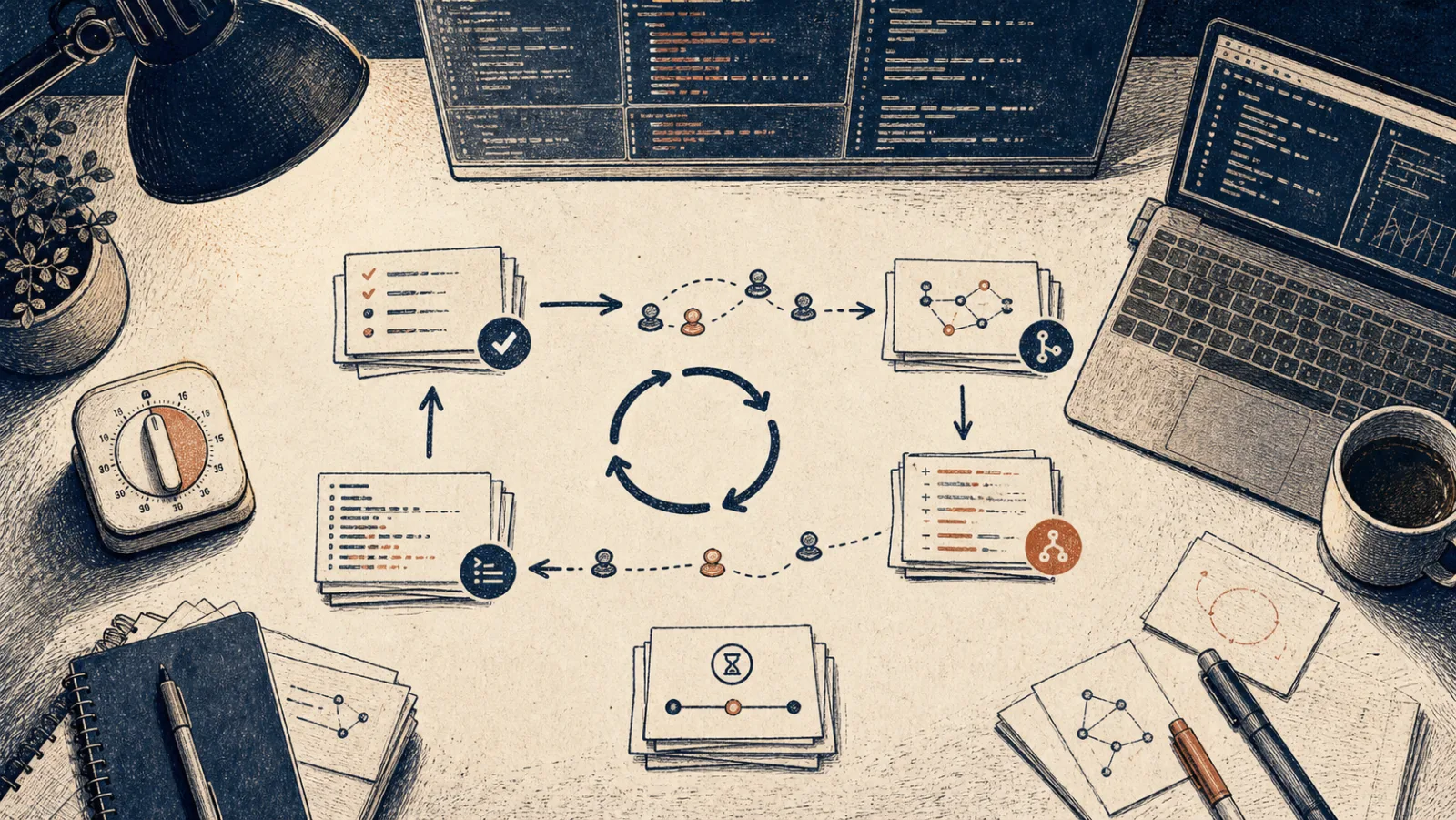
/loop 适合在 CLI 里做短周期轮询,Routines 适合云端定时和事件触发,生产化 harness 还需要队列、状态、幂等、补偿、审计和人类控制面。
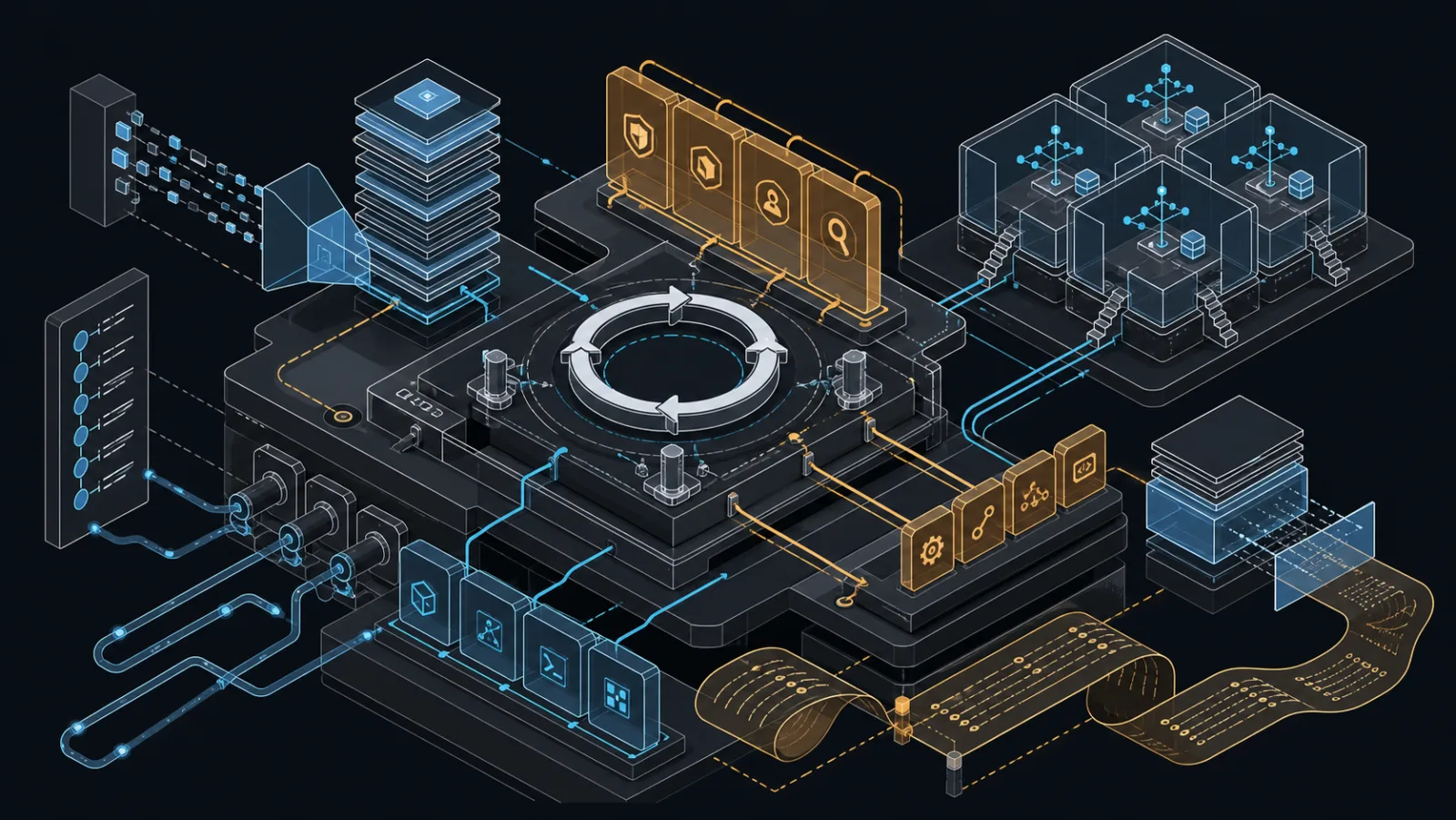
Claude Code 的核心不是一个模型加一个 shell,而是由上下文装载、工具执行、权限规则、hooks、skills、subagents、MCP 和 compaction 组成的 agentic runtime。